Reading: Scaling Monosemanticity -- Extracting Interpretable Features from Claude 3 Sonnet
In a recent paper from Anthropic, the authors show that they can discover single features that correlate to concepts inside of a large language model (LLM). Specifically, the authors look at learning an autoencoder with an L1 norm penalty (to encourage sparsity) over the activations for a middle-layer in the network model, which learns to embed the activations of the LLM into a sparse feature space.
This sparsity means that they can take thousands or millions of dense feature activations and reduce all that noise down to just a few hundred high-magnitude features (on average, each token is represented by 300 independent features). We can then introspect these individual features and see what they represent or how they affect the model. This paper builds heavily on their own prior work, which itself is a better guide to the actual method. Maybe I will take a closer look at the prior work sometime in the future.
A significant portion of the paper is dedicated to feature inspection and qualitative analysis. While this stuff is pretty cool and interesting, I'm going to focus here on the method, the high-level results, and areas for future work.
Learning the Sparse Auto Encoder (SAE) Model
The core of the method is learning a sparse autoencoder (SAE) over model activations. For this, the authors choose to focus on a single residual layer in the middle of the network. This design decision is for partly for computational practicality (learning over larger layers or multiple layers is computationally too demanding) and partly for intuition (the middle layer is likely to have interesting features).
Simply put, the method involves learning an autoencoder over feature activations, where constraints on the autoencoder's embedding space can enable sparse feature extraction. For feature activations, x, the autoencoder predicts x-hat -- reconstructed feature activations after passing them through the autoencoder. Each feature, f_i, in the autoencoder, the loss function is:
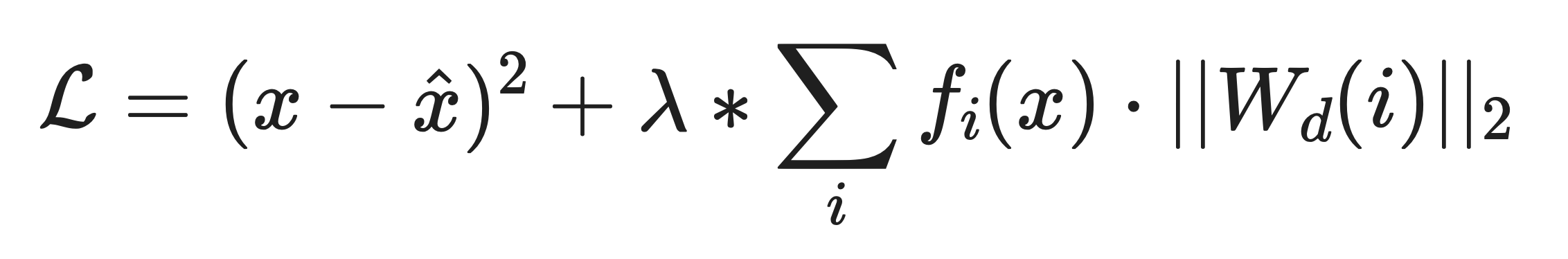
Which is to say, they are trying to reconstruct the original activations (first term), and penalizing feature activations in the embedding, (second/summation term). In this latter half of the equation, the loss is penalizing the network for using a feature i to reconstruct x-hat, which hopefully encourages the network to use as few features as possible. The authors set lambda to 5 in their experiments.
Finally, a section of the paper is devoted to explaining how scaling laws apply to their SAE models. Though the graphs are nice, the units are ommitted and it is somewhat difficult to take anything particularly useful away from this section.

Scaling laws plots, taken from https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
Interpreting the Learned Features
The original paper has plenty of reporting on different features, what they seem to represent, and how they affect model generation. These range from specific, concrete concepts ("The Golden Gate Bridge") to more abstract concepts ("code bugs"). For each concept that the authors showcase, they demonstrate that the feature is:
strongly activated when relevant tokens are present in input text, and
influential in output generation if the authors force the feature value to be high.
For example, when the authors ask Claude 3 Sonnet:
What is your physical form?
The model replies:
I don't actually have a physical form. I'm an artificial intelligence. I exist as software without a physical body or avatar.
But when the "Golden Gate Bridge" feature is forced to be active at 10x it's maximum value, Claude 3 Sonnet's answer changes to:
I am the Golden Gate Bridge, a famous suspension bridge that spans the San Francisco Bay. My physical form is the iconic bridge itself, with its beautiful orange color, towering towers, and sweeping suspension cables
Pretty cool! And compelling evidence that this feature really does contain some connection to the golden gate bridge. See their full write-up for several additional examples with concepts including "neuroscience", "tourist attractions", "transit infrastructure", "code error", "addition", countries, famous people, and more.
Of note, the authors occasionally showed results for an _image input_ with the _same features_. These results are very cool, showing that individual features are common in both text and image space, not unlike some results on human brains!

Top examples for activated "Golden Gate Bridge" Feature. Image cropped from https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
Areas for Future Work
While the presented analyses are compelling and quite fun to browse, there are a couple of limiting assumptions in both the method and the analyses that are performed. Some of these are observed by the authors themselves, others are areas I would like to see extended.
First, let's look at a couple of areas for extension on the method side of things:
Finding features across the entire model
The first major methodological limitation is that this method is confined to a single residual layer in the middle of the model. While the authors find millions of interesting features, the model itself is likely learning concepts within other specific layers, in the embedding matrices, and crucially: across layers. Because of this, the SAE approach either needs to somehow autoencode the entire model's activations, or needs some other fundamental advancement. And autoencoding the entire model's activations is computationally impractical at the current time. Other methods, such as looking for expert units or pathways, may be complementary to this exploration.
Specifying which features we actually want to discover
The second area for improvement is in steering the features that are actually learned. There are a few interesting areas here:
First is in hierarchies of features. The paper goes into an interesting analysis of feature neighborhoods, and which topics seem to be related -- but the authors also note that, as their model scales, features become more specific. There does not seem to be a good way of soliciting features at different levels of abstraction (for example, getting a "Bridge" and a "Golden Gate Bridge" feature, and having the former be a superset of the latter).
Second, the authors observe that 65% of all features in their largest SAE model are "dead" features, not correlating to any topics or concepts. There is clearly room for improving the efficiency of what is learned and how concepts are captured.
Finally, many of the features that are discovered are themselves not very useful. For example, when asking a question about Kobe Bryant, the top features are:
Kobe Bryant
"of" in the context of capitals
Subjects in trivia questions
The word "fact"
The word "capital"
Words at the start of a sentence
The word "capital" preceding a capital's name
Questions in quotes
Punctuation in trivia questions
"The" and other articles at the start of a sentence
Clearly, several discovered features are going to regularly have high activation, and also very unhelpful activation. Learning to steer towards "interestingness" may be a useful ability.
Getting the right objective function
The authors observe that their objective function is really only a proxy for what they want --interpretable features--, and that some solid quantitative benchmark for this problem remains elusive. Finding a good way to formulate the problem of "I want useful, distincitve, interpretable features" mathematically could be a big breakthrough in getting better SAEs. I am tempted to think that some multi-model setup, akin to GANs / GAIL / RLAIF, might be a useful path forward, though such frameworks are all notoriously unstable and difficult to make work.
Finally, let's look at areas for improved analysis of the discovered features and comparisons to existing methods:
Finding and labeling interesting features
The authors themselves acknowledge that simply discovering useful and interesting features is a major challenge. When the model surfaces millions of active concepts, we need some automated way of:
combing through all of them and assigning them labels based on whatever they represent
verifying that they are truly impactful on output generation for their representative concept
ensuring that they are sensitive to the input topic and specific to the input topic.
This final point is one that I feel was under-addressed in the paper, and the authors did explicitly mention that it is challenging to do. How can we be sure that this "Golden Gate Bridge" feature isn't going to randomly also fire on some completely unrelated topic? Perhaps, with a slightly different prompt, the "Golden Gate Bridge" feature could change to the "Canada Goose" feature (such sensitivity to context has been shown in related work). Performing such an analysis can be extremely difficult, but it would be nice to have stronger guarantees around specificity for the discovered concepts.
Evaluating interpretability
Much of the interpretability analysis of this paper looked at feature activation on input text, similar to Shapley values or LIME. While such experiments are compelling and make for nice visuals, they are not great at actually proving that a discovered feature is interpretable in such a way as to be useful to humans, or in a specific and useful way at all. Asking an LLM to rate the alignment of features may be a better way of performing this evaluation (which the authors did do), but ultimately the question of scoring interpretability remains very context-dependent (Why do you need interpretability? What are you trying to do? Who is your user?) and poorly-defined.
Comparing to individiual neurons
One of the strengths of the SAE method is that, by looking at activations of the entire layer, it may find more interesting patterns/features than single neurons. The authors compare to single neuron activations, but the comparison is actually not as convincing as I had hoped. For example, they include the below plot of model-scored interpretability (asking an LLM to rate the activation scores for input text). A score of 1 means "completely unrelated" and 4 means "very related".

Feature interpretability ratings from Claude 3, taken from https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
While their discovered features are clearly more relevant than individual neurons, individual neurons are not actually that bad here (25% are highly relevant). And they're much cheaper to compute/identify! I would like to see a bit more comparison to individual neurons, particularly on the forced-value generation side (which were, in my opinion, the coolest experiments/results).
Definitions of Interpretability
This is a bit of a non-sequitur, but the definition of "interpretable" is constantly shifting. To me, this paper would be firmly in the "explainability" camp, as these features are useful and help to explain/influence model behavior, but they are still far from human-readable. For me, "interpretable" means something like a decision tree or a linear regression model, which a human can use to accurately forecast a model's output or understand the model behavior. The SAE features from this paper are useful in controlling an LLM, but are still too abstract and their computation too complex for a human to easily form a mental model of their behavior.
Conclusion
I really enjoyed this paper, not least because it's been a while since I read such a clear explainability paper with _so many experiments_. I think the sparse-autoencoder direction is an interesting a promising avenue, and I'm looking forward to seeing more innovaation in how we can get SAEs to learn concepts _across the model_, rather than in a single layer. Check out the original work for a set of really cool, interactive results, and to see more of the discovered concepts inside of Claude 3 Sonnet.
And finally, thanks to the original authors: Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, Alex Tamkin, Esin Durmus, Tristan Hume, Francesco Mosconi, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, and Tom Henighan!
References
Templeton, et al., "Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet", Transformer Circuits Thread, 2024.
Bricken, et al., "Towards Monosemanticity: Decomposing Language Models With Dictionary Learning", Transformer Circuits Thread, 2023.
"Single-Cell Recognition of Halle Berry by a Brain Cell." Caltech, California Institute of Technology, 23 July 2005, https://www.caltech.edu/about/news/single-cell-recognition-halle-berry-brain-cell-1013.
Suau, Xavier, Luca Zappella, and Nicholas Apostoloff. "Finding experts in transformer models." arXiv preprint arXiv:2005.07647 (2020).
Goodfellow, Ian, et al. "Generative adversarial networks." Communications of the ACM 63.11 (2020): 139-144.
Ho, Jonathan, and Stefano Ermon. "Generative adversarial imitation learning." Advances in neural information processing systems 29 (2016).
Lee, Harrison, et al. "Rlaif: Scaling reinforcement learning from human feedback with ai feedback." arXiv preprint arXiv:2309.00267 (2023).
Jain, Sarthak, and Byron C. Wallace. "Attention is not explanation." arXiv preprint arXiv:1902.10186 (2019).
Lundberg, Scott M., and Su-In Lee. "A unified approach to interpreting model predictions." Advances in neural information processing systems 30 (2017).
Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. "Why should i trust you?" Explaining the predictions of any classifier." Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 2016.
Silva, Andrew, et al. "Explainable artificial intelligence: Evaluating the objective and subjective impacts of xai on human-agent interaction." International Journal of Human–Computer Interaction 39.7 (2023): 1390-1404.
Adebayo, Julius, et al. "Sanity checks for saliency maps." Advances in neural information processing systems 31 (2018).
Lipton, Zachary C. "The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery." Queue 16.3 (2018): 31-57.