Simplifying MuZero in "Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model"
DeepMind’s Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model was officially published today in Nature, and is a reasonably short read covering a cool direction for future reinforcement learning (RL) research.
What is the paper trying to do?
Following the incredible successes of AlphaGo and AlphaZero, this work introduces MuZero, which permits the extension of AlphaZero-like learning and performance to a new set of RL domains.
AlphaZero learned to master Go and Chess through the use of a simulator— RL agents use forward-simulation from each state in order to accurately estimate which move is the most valuable. So, from any given board state, the AlphaZero agent simulates many moves into the future, helping it to decide which move will yield the best long-term reward. Crucially, this only works if you have an accurate simulator. We can’t forward-simulate hundreds of steps for a task without a simulator.
MuZero takes a step toward removing this restriction. The agent here learns to predict environment dynamics as they relate to the agent’s success, permitting forward-simulation without actually having a simulator. This is a really cool approach, basically trying to approximate a simulator specifically for the learning agent’s performance, not for actually simulating the task. We don’t care about simulating future board states, we only care about simulating future state values, rewards, or actions.
What do they actually do?
The authors use Monte Carlo Tree Search (MCTS) to choose future actions based on their learned forward simulator, the same way that AlphaZero chose actions based on the real simulator. Using MCTS to generate hidden-state roll-outs of the task (rather than full-on simulations), MuZero then learns 3 separate functions: the policy estimator, the value estimator, and the reward estimator. Each of these 3 functions uses the same hidden state, providing the signal for MuZero to learn a useful simulation function.
The policy estimator predicts which action should be taken for a given simulator step, the value function predicts the discounted reward (or value) back to a given simulator step, and the reward function predicts the reward value for a simulator step. Taken together, these three estimators provide all of the information that the MCTS actually needs to forward-simulate a game. The agent doesn’t need to know what the state actually looks like, it just needs to know which action it should take and what the estimated value and reward of the states are.
Does it work?
MuZero works impressively well, as shown in the figure below (taken from the paper). The orange line represents AlphaZero's performance for Go, Chess, and Shogi, and we can see that MuZero learns to replicate (and even exceed) AlphaZero’s performance in these domains (AlphaZero has access to a perfect simulator). In the Atari domain, the orange line is the prior state of the art, and again MuZero is able to exceed the baseline.
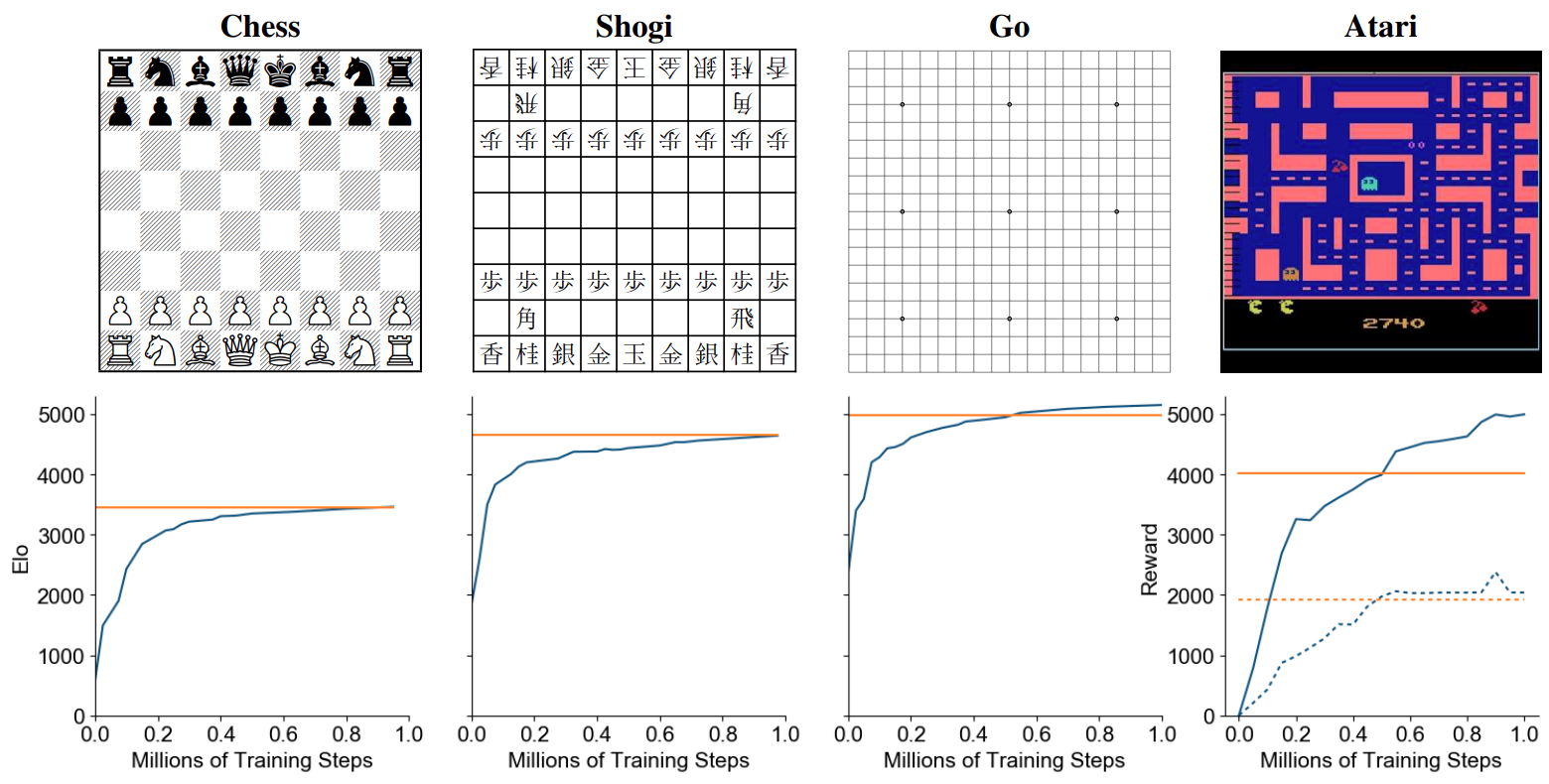
Orange represents AlphaZero for Go, Chess, and Shogi, and it represents the prior state of the art for Atari. In all cases, MuZero meets or exceeds the baselines, showing that MCTS with a learned, agent-specific simulator is a viable and successful approach to learning high-performing policies in domains without having access to simulators. Image taken from https://arxiv.org/abs/1911.08265
What can researchers take away from this paper?
1) You don’t need perfect simulators.
MuZero is a strong example for not needing perfect simulators and for not recreating input states. It’s common to use some type of auto-encoder to pre-train a vision system in RL, or as an auxiliary loss to encourage the learning of useful embeddings. The authors in this work emphasize that pixel-perfect recreation isn’t useful to the agent, and it isn’t what we really care about. What we want is a useful policy and accurate estimates of future reward, not accurate estimates of future input states. So why not just try to optimize our hidden states and embeddings for the tasks we care about?
2) Combine planning with deep-RL
Both AlphaZero and now MuZero make a strong case for combining MCTS with more conventional deep-RL. Simply estimating actions and values is useful, but combining that with a look-ahead for longer-term planning is much more useful. Further, it seems necessary at the moment, as our agents don’t necessarily learn foresight or implicitly learn to plan on their own.
Closing Thoughts & Discussion
AlphaZero generated an incredible amount of buzz, but without access to staggering compute and accurate simulators, replicating AlphaZero hasn’t exactly been practically viable for many researchers.
MuZero addresses one of these issues, but not the other. While we can now think about extending MCTS and deep-RL to a wider variety of domains, the actual process of MCTS + deep-RL still takes a seriously impressive amount of compute power and time, something that most academia researchers won’t realistically be able to replicate on the scale that a Google DeepMind can.
I’m very curious to see some of the directions that DeepMind can take this technology. We’ve seen some of the lines of research like AlphaFold or Imitating Interactive Intelligence attack other interesting problems, problems which might benefit from learning the dynamics of the world and incorporating forward-simulation for planning. In particular, it would be very interesting to use human-expert trajectories to learn the hidden-state simulator, potentially reducing the compute needed for MuZero.
Finally, I’m curious about the possibility of extracting a human-usable planner from MuZero. One of the reasons the algorithm works so well is that it doesn’t need to learn human-interpretable state dynamics, but this is also a limitation for many domains. If we could apply MuZero to learn a simulator of disease progression, we’d love to be able to open up that simulator and better-understand the dynamics for ourselves. Such pushes for human-interpretable simulators could be very useful in many domains.
References and other useful resources:
Abramson, Josh, et al. "Imitating Interactive Intelligence." arXiv preprint arXiv:2012.05672 (2020).
Silver, D., Huang, A., Maddison, C. et al. Mastering the game of Go with deep neural networks and tree search. Nature 529, 484–489 (2016). https://doi.org/10.1038/nature16961
Silver, David, et al. "A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play." Science 362.6419 (2018): 1140-1144.
Schrittwieser, J., Antonoglou, I., Hubert, T. et al. Mastering Atari, Go, chess and shogi by planning with a learned model. Nature 588, 604–609 (2020). https://doi.org/10.1038/s41586-020-03051-4