Interpretable Machine Learning: What is Interpretability?
In my last post, I wrote a bit about why we want interpretability and what that means to end-users. In this post, I’ll explore a bit about what that means to practitioners and researchers, and two main ways to accomplish the goal of understanding our machine learning systems.
What does interpretability mean?
It turns out that rigorously defining “interpretability” is somewhat challenging. People often have one of two key areas in mind when they talk about interpretability in machine learning. The same paper referenced in my prior post, The mythos of model interpretability, highlights the two primary thrusts, calling them transparency and post-hoc explanations.
Transparency
One path to interpretable models is models which a human can look at and entirely understand/reproduce. If we consider something like a small flowchart, we can always follow from input to output with just a few steps. The model is clear, it’s easy to interpret, and it offers insight into why decisions are being reached.

Transparent Algorithm
Looking at the process for loan approval on the left, we immediately know exactly how it works and what to expect for every new person.
Many classic machine learning approaches lend themselves nicely to transparency. As long as they stay sufficiently small, things like decision trees or regression classifiers are easy to follow and understand. However, as the models begin to grow, they quickly become unwieldy and useless to humans. A decision tree with a thousand nodes, for example, is not a transparent model. Even though each individual decision is clear, nobody is going to memorize a thousand nodes and combinations to get a full mental map of the model.
Explanations
An alternate approach to interpretability is to provide explanations with outputs from a machine learning system. These explanations can take a variety of forms, with one of the most common being text explanations. As in the appendicitis example above, a system might provide a natural language sentence in addition to a final classification, providing humans with more context for a decision. Alternative approaches to post-hoc explanations include things like attention layers (visualizing what the model “looked at” when making a decision) or similar examples.
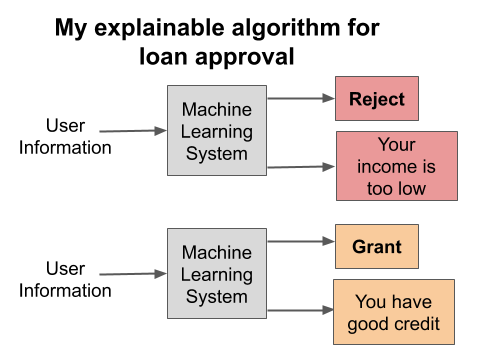
Explainable Algorithm
Explainable algorithms produce both a decision and an explanation for each input, describing how they make each decision, as in the two examples on the left.
A major drawback of post-hoc explanations is that, inherently, we never see what’s really going on behind the scenes. Humans may need to see dozens of explanations before they get a good sense of how the model works, and even then they will likely not be able to predict how it will handle unseen data. In the worst case, explanations will only serve to perpetuate bias by using some undesirable features (such as race or gender) to make a decision, but failing to mention the use of that data in an explanation. Recent work has also called the use of attention mechanisms into question [2, 3], though the debate around attention is ongoing [4].
For a full review on all of the ways that explainability fails and even deceives humans, see “Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead” by Dr. Cynthia Rudin.
Other Approaches
There are, of course, plenty of ways that people attack the interpretability/explainability problem. In “Understanding Black-box Predictions via Influence Functions”, the Best Paper at ICML 2017, there is a math-heavy way of identifying which samples in the training set are responsible for a prediction. Google Brain has a cool distill.pub article on “Building Blocks of Interpretability”, where they cover different ways to discover concepts which make models more interpretable to humans. Another approach is to use a topic model to cluster salient concepts together [6], though this can fall into the trap of pitting accuracy and interpretability against each other [7].
Wrapping Up
Interpretability is complicated. As Cynthia discusses in her work, there is a sizable gap between intrinsic interpretability (transparency) and explainability or post-hoc explanations. Often, there is a perceived tradeoff between accuracy and transparency, with the implication being that one cannot obtain the best performance while being perfectly interpretable. To that end, much research is currently going on around explainability, attempting to learn to rationalize decisions after they’ve been made.
While transparent models may be harder to create while preserving some high degree of accuracy, it seems very reasonable to expect researchers to work on methods which encourage both interpretability and accuracy, attempting to maximize both simultaneously, though these may be very difficult to discover. Many guidelines or processes in the real-world are constructed as perfectly interpretable and transparent flowcharts, offering clear pictures about how a process works while still enforcing some optimal set of behaviors [9]. Even so, many challenges remain before we have a set of interpretable models performing well out in the real world.
References
[1] Lipton, Zachary C. "The mythos of model interpretability." arXiv preprint arXiv:1606.03490 (2016).
[2] Vashishth, Shikhar, et al. "Attention interpretability across nlp tasks." arXiv preprint arXiv:1909.11218 (2019).
[3] Kindermans, Pieter-Jan, et al. "The (un) reliability of saliency methods." Explainable AI: Interpreting, Explaining and Visualizing Deep Learning. Springer, Cham, 2019. 267-280.
[4] Wiegreffe, Sarah, and Yuval Pinter. "Attention is not not Explanation." arXiv preprint arXiv:1908.04626 (2019).
[5] Rudin, Cynthia. "Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead." Nature Machine Intelligence 1.5 (2019): 206-215.
[6] Doshi-Velez, Finale, Byron C. Wallace, and Ryan Adams. "Graph-sparse LDA: a topic model with structured sparsity." Twenty-Ninth AAAI Conference on Artificial Intelligence. 2015.
[7] Chang, Jonathan, et al. "Reading tea leaves: How humans interpret topic models." Advances in neural information processing systems. 2009.
[8] Olah, Chris, et al. "The building blocks of interpretability." Distill 3.3 (2018): e10.
[9] Gawande, Atul. Checklist manifesto, the (HB). Penguin Books India, 2010.